When an event-driven system grows, it usually fails in predictable places: consumer lag creeps up, retries start to overlap, and the database turns into an accidental coordinator for “who processed what.” Past that point, shaving milliseconds off a handler rarely matters. The bottleneck moves to architecture - where state lives, how concurrency is controlled, and which failures are allowed to cascade.
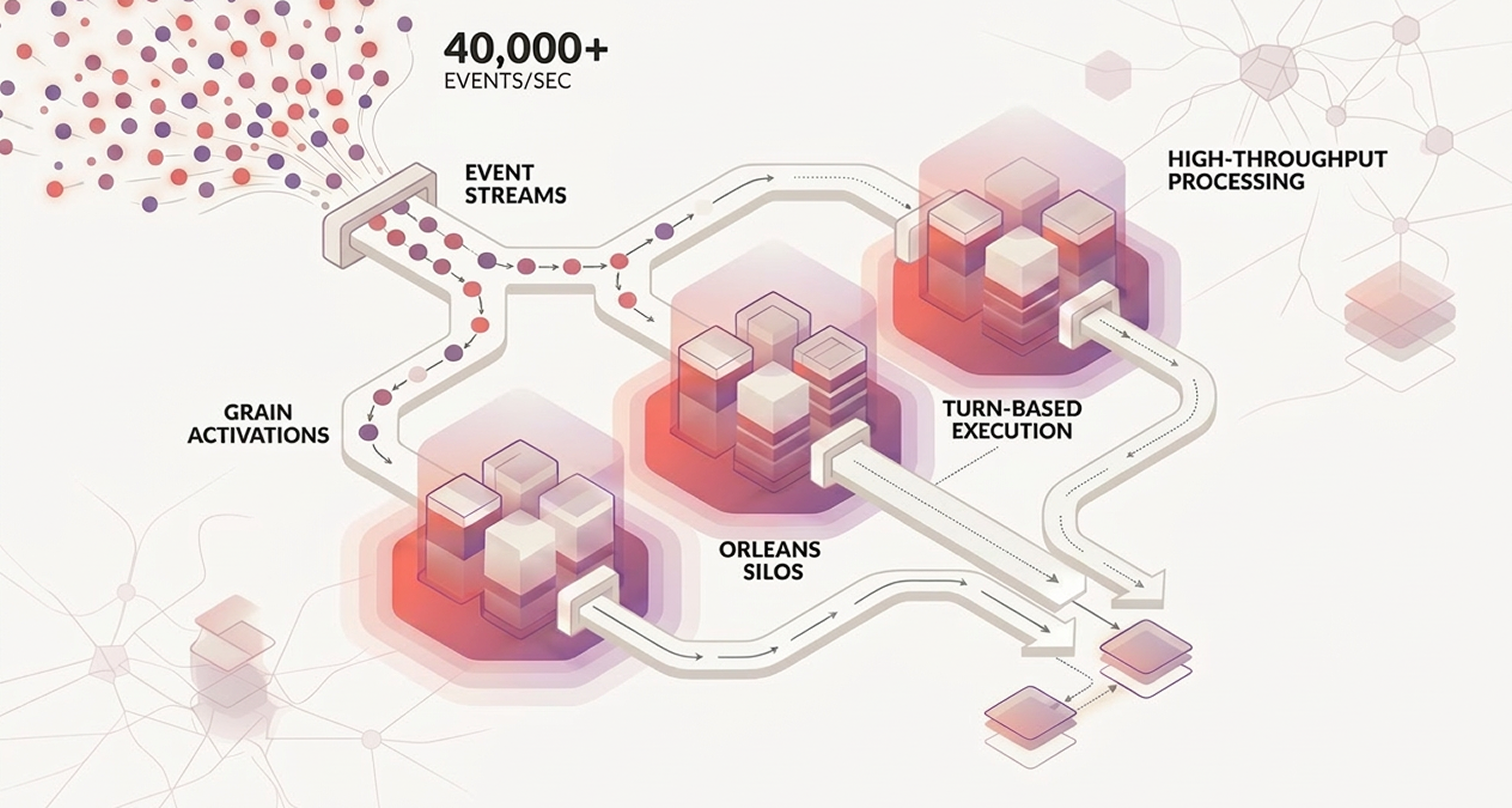
In this case study, Managed Code engineers used the Microsoft Orleans framework to build a multi-agent architecture (virtual actors) for high-throughput event processing. In load tests, the system processed over 40,000 events per second on small Azure VMs while keeping latency stable. This write-up focuses on the mechanics that made that possible: partitioning, Orleans Streams, grain placement, idempotency, and a benchmark method that keeps results defensible.
Choose Orleans when your workload can be partitioned by a stable key (account, device, tenant, order) and you need stateful concurrency per key without rebuilding your own distributed lock manager. Consider alternatives when you need strict global ordering across all events, or when your success criteria demands single-digit millisecond hops that are difficult in a multi-node actor cluster.
If you want a quick primer on the virtual actor model before you dive into performance tuning, read the official Orleans overview.
Tens of thousands of events per second sounds straightforward until you add the constraints that make those events valuable. Each event belongs to an entity, each entity has evolving state, and the system still has to make correct decisions when deliveries repeat and nodes restart. You can scale stateless consumers almost forever, yet correctness and latency tend to collapse when state coordination is handled indirectly through a shared database or a fragile “exactly once” promise upstream.
For this engagement, four constraints were non-negotiable: sustain burst throughput without lag, keep tail latency stable when retries appear, stay correct under at-least-once delivery, and keep operations simple enough to scale by adding nodes instead of building custom sharding infrastructure. In plain terms, we needed a system that stayed calm when traffic and failures arrived together. That pressure pushed us toward an actor-style model. State stays isolated, per-entity updates stay serialized, and partitioning is designed up front.
The decision driver was state ownership. We wanted a system where “entity state” is owned by one place at a time, where concurrency is controlled by construction, and where horizontal scale comes from partitioning, not from spreading locks across services.
Orleans gives you that through grains: - A grain activation executes one request at a time, which lets you write sequential logic and keep invariants intact without scattering locks through the codebase. - The runtime handles activation lifecycle and placement across a cluster of silos, so you can scale out without hand-rolling routing tables.
At the code level, microsoft orleans grains are the per-entity agents - they own state, accept events, and emit follow-up work.
The biggest mindset shift is turn-based execution per entity. A user grain can receive a heavy burst of requests, yet it still applies them one by one in arrival order. That gives each user a consistent mutation lane in practice.
Consistency also holds when the cluster has many nodes, because a regular grain key has one active owner at a time and Orleans routes calls to that owner. Teams usually remove per-user distributed locks, and the grain itself becomes the coordination primitive for per-entity invariants.
This model changes how teams reason about throughput. Per-user execution stays sequential, while system throughput scales through parallel users processed across many grain keys and silos. In high-load windows, the cluster behaves like thousands of independent per-entity queues, each one consistent on its own boundary. That is the practical reason Orleans often removes a large class of race conditions from product code.
It also changes how teams design write paths. Invariant logic moves into the grain boundary first, side effects are coordinated after state is safe, and distributed locks become a targeted tool for cross-system coordination instead of a default building block for everyday per-user consistency.
We also tracked version-specific behavior through the Microsoft Orleans GitHub repository, since placement defaults and hosting details can shift between releases.
We still treat Akka.NET as a serious alternative in .NET actor systems, especially with Akka.Hosting making it easier to run under Microsoft.Extensions.Hosting. Akka.NET can be a better fit when you want explicit actor hierarchies and supervision, or when your team already runs Akka-style clusters comfortably. For this system, the Orleans virtual actor model matched the “many entities, each with state and a message stream” shape more directly. That reduced how much custom infrastructure we had to maintain.
For the design rationale behind virtual actors, the original MSR technical report is still a useful reference: Orleans: Distributed Virtual Actors for Cloud Computing.
In this case study, “multi-agent” means one simple thing: each agent is a virtual actor with a clear identity and responsibility boundary. In Orleans terms, agents are grains.
At a high level, each event goes through four predictable moments: - it enters from a broker into Orleans Streams - stateless workers normalize and route it by partition key - one entity grain applies it in strict sequence - side effects execute behind retry and idempotency controls
That order matters, because it keeps business state coherent before the system touches dependencies that can fail in messy ways.
Microsoft Orleans Streams provide the “wiring” for this design. Streams are virtual abstractions over real transports, and delivery semantics depend on the chosen provider. That is fine as long as the architecture assumes duplicates are possible and implements idempotency where it matters.
For the stream model and provider-level semantics, the official Orleans Streams docs are the best reference point: Streaming with Orleans
Below is a minimal grain that shows the core pattern we used: sequential event application with explicit persistence and an idempotency check. It is intentionally plain - the performance work is in what you choose as a key, what you store, and how you bound side effects.
public interface IEntityAgentGrain : IGrainWithStringKey
{
Task HandleAsync(EventEnvelope evt);
}
public sealed class EntityAgentGrain([PersistentState("state")] IPersistentState<EntityState> state) : Grain, IEntityAgentGrain
{
public async Task HandleAsync(EventEnvelope evt)
{
if (state.State.Seen(evt.Id))
{
return;
}
state.State.Apply(evt);
state.State.MarkSeen(evt.Id);
await state.WriteStateAsync();
}
}
In production, the “Seen” logic is usually a bounded dedupe window (by time or by count), and persistence is often batched or coalesced to avoid one write per event. The grain shape stays similar.
High throughput in Orleans came from a handful of decisions we kept repeating under load, even when shortcuts looked tempting. None of these choices is exotic. The hard part is applying them consistently when the system is under pressure.
Throughput scales when work spreads across many keys, yet real traffic rarely behaves like a clean average. In most production streams, a small set of keys dominates volume, and those hot keys can stall the rest because each grain processes sequentially. We treated skew as the default failure mode, not a corner case.
When a natural key turned out too hot, we introduced sharding only for those hot entities, for example by category or time bucket. We also ran skewed-load tests alongside uniform baselines, because uniform tests look healthy right up to the point where production fails.
The practical checks were simple: - if top keys dominated traffic, we split only those keys - if skew tests diverged from uniform tests, we tuned key strategy before scaling
The quickest way to kill Orleans throughput is to block inside a grain turn. We treated slow I/O, synchronous library calls, and heavy CPU work as risks that had to be isolated, rate-limited, or moved outside the critical path.
In practice, that meant async I/O end-to-end, explicit separation between decision grains and side-effect execution, and bounded edge concurrency. This kept one broken dependency from triggering a retry wave across the cluster.
Validation, normalization, cache enrichment, and routing are mostly stateless transformations. Binding that work to per-entity grains adds contention without improving correctness. Stateless worker grains let those stages scale by parallel activations. That kept ingestion resilient during spikes and left entity grains focused on stateful decisions.
Placement decides how quickly a cluster settles under load. Orleans supports several placement strategies, and starting in Orleans 9.2 the default becomes ResourceOptimizedPlacement, which incorporates CPU and memory utilization.
The grain placement docs cover the available strategies and the Orleans 9.2 default in more detail: Grain placement
Each microsoft orleans silo is a host process that runs grain activations; scale-out is mainly a matter of adding silos and keeping placement behavior predictable under skew.
Our operating goal was simple: add silos to scale out, let the runtime distribute activations, and change placement settings only when telemetry shows thrash signals. We tracked activation churn, memory pressure, and sustained CPU pegging.
Distributed event pipelines almost always become at-least-once somewhere, even when a single component claims otherwise. We treated that as a design premise and built the reliability model around it.
The turning point came when we stopped treating duplicate delivery as an edge case. We treated it as normal operating mode. Every event carried an idempotency key, and each entity grain kept a small window of processed keys, or a sequence number where strict ordering was available. This discipline made retries safe. It also moved duplicate handling from incident response into regular telemetry.
The second turning point was procedural. External side effects never ran as open-ended loops. Each event had a retry budget for attempts and elapsed time, a backoff schedule tuned to dependency behavior under load, and a clear idempotency boundary that made retries safe. When a downstream dependency started failing, we degraded on purpose instead of letting retry storms burn cluster capacity. That choice kept tail latency stable during partial outages.
Orleans persistence is explicit - grain activation loads state, and writes happen only when you call them. That means storage decisions are part of the correctness model, not an implementation detail. We treated Microsoft Orleans grain storage as a contract and separated required state mutations from outputs we could rebuild. We also split immediate writes from batch-safe writes with clear thresholds. That kept completion semantics clear and replay behavior predictable during partial recovery.
Performance claims without a measurement plan are marketing, even when the underlying engineering is solid. We treated observability as part of the architecture and instrumented the pipeline so “where is the time going?” was answerable in minutes.
We tracked three signal families: - Flow - ingest rate, processing rate, lag, backlog, queue depth - Latency - end-to-end latency plus stage-level p95/p99 contributors - Reliability - retry rate, timeout rate, dedupe hits, poison events, storage write failures
Together, these signals let us answer the only question that matters during incidents: where exactly the delay or correctness drift started, and what lever fixes it fastest.
The practical goal was simple: when latency rises, we can point to the stage responsible and decide whether the fix is more capacity, less work per event, or a change in dependency behavior.
The headline result from load testing was throughput: the Orleans-based multi-agent architecture processed over 40,000 events per second on small Azure VMs while maintaining consistent latency.
We do not consider “consistent latency” publishable until it has numbers behind it. For a final release, we recommend filling the table below with the actual observation windows and p50/p95/p99 values from production telemetry or a documented benchmark run.
The actor model makes concurrency easier inside an entity boundary, then forces you to be honest about everything outside that boundary: partitions, delivery semantics, persistence, and backpressure. Those are the decisions that determine whether “Orleans feels fast” in dev turns into “Orleans stays fast” in production.
These triggers are the ones we use most often when scaling a Microsoft Orleans system. They are intentionally concrete so they can be turned into alerts and runbooks.
A quick decision note on “microsoft orleans vs dapr”: if you primarily need a portability layer and a lightweight actor abstraction around external state, Dapr can be a good fit. If you need deep control over a high-throughput stateful execution model inside .NET, Orleans is usually the more direct tool. In both cases, the foundation stays the same: define delivery semantics, build idempotency, and measure tail latency under skew.
If you want performance numbers people can trust, treat benchmarking as part of the product and not as a one-time screenshot. We use a simple four-part recipe: define workload shape, lock success metrics before the run, isolate bottlenecks in staged benchmarks, and publish the exact run envelope so another team can reproduce the result.
In practical terms, the run plan is always the same: - document workload shape first (event sizes, key cardinality/skew, stateful-event share) - lock success metrics before testing (throughput, p50/p95/p99, error/retry/duplicate rates, per-silo utilization) - run staged benchmarks (in-memory baseline, then persistence, then realistic side effects with fault injection) - publish the full envelope (Orleans version, hosting model, node sizes/count, placement settings, broker/provider config, warm-up and observation windows)
That is what turns a strong benchmark claim into a result another team can reproduce and trust.
That is how “40,000 events per second” becomes an engineering fact instead of a number on a slide.
It took the Managed Code team five months to build the application, as initially planned. The app that Managed Code developed runs smoothly, is highly rated by users, and helps the client generate a steady profit. The team was highly communicative, and internal stakeholders were particularly impressed with Managed Code's expertise.
Their professionalism and commitment to delivering high-quality solutions made the collaboration highly successful.
Thanks to Managed Code's efforts, the AI assistant significantly improved the client's ability to serve new and existing clients, resulting in increased customer satisfaction and higher sales. The team was responsive, adaptable, and committed to excellence, ensuring a successful collaboration
We're impressed by their expertise and their client-focused work.
With an excellent workflow and transparent communication on Google Meet, email, and WhatsApp, Managed Code delivered just what the client wanted. They effortlessly focused on the client's needs by being client focused, as well.