Patent work fails at the seams: deadlines live in calendars, the evidence lives in PDFs and drawings, and the most important details often show up as a footnote in the document you did not open. We built an AI patent attorney agent to make that seam visible and manageable - by turning every answer into a reviewable work product that points back to specific evidence.

This case study covers a practical slice of patent and trademark work: intake, retrieval, evidence linking, and drafting support. The short conclusion is simple. An agent is useful when it behaves like a careful paralegal who cites what it read, and it becomes dangerous when it behaves like a persuasive writer.
If you need repeatable, review-driven outputs from mixed files (PDFs, office actions, drawings, email threads), this approach is a fit. If you are looking for automatic patentability decisions or automatic trademark clearance, the safest version of this system is the one that refuses the job and routes it back to a human.
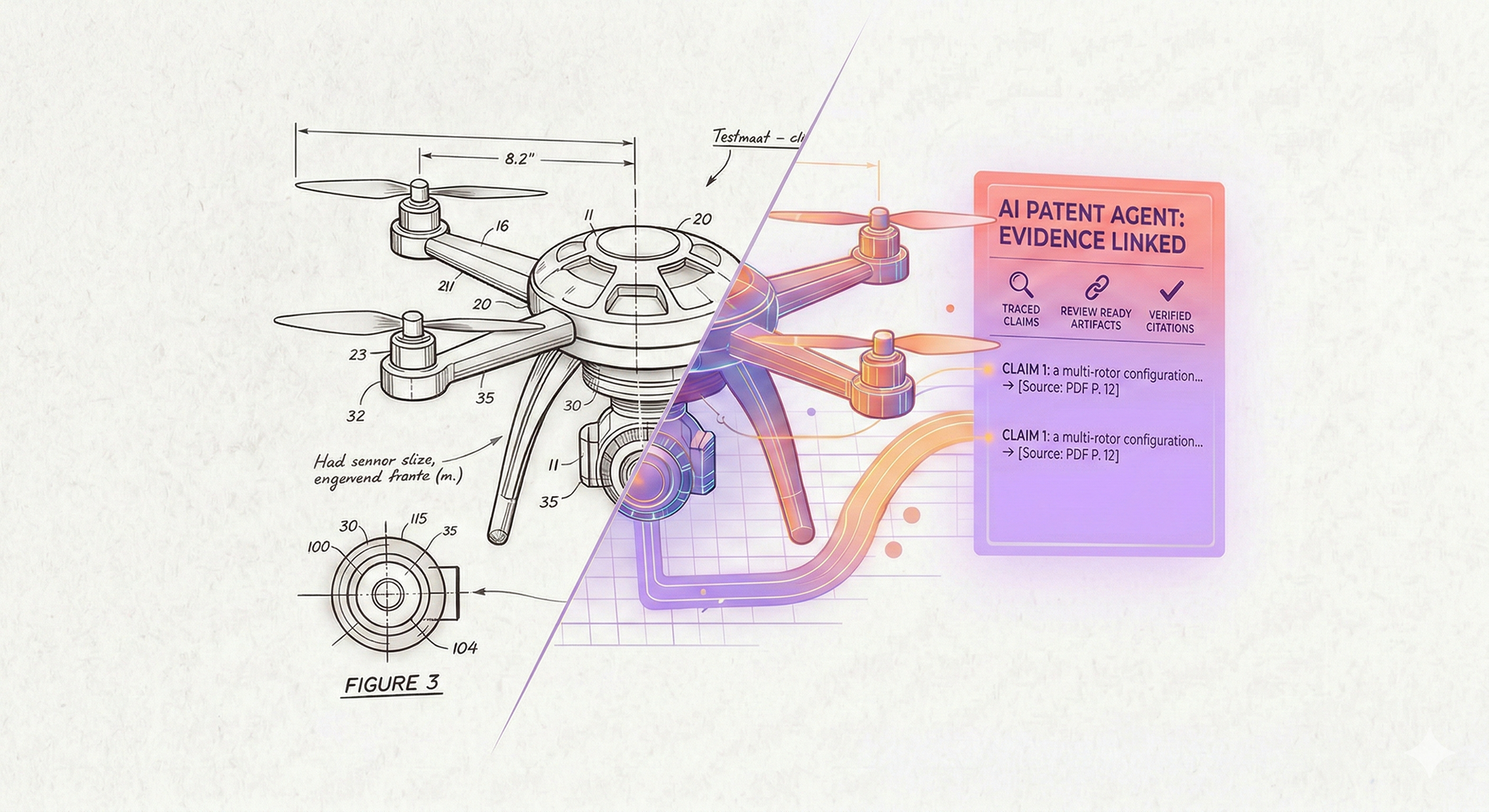
Day to day, the agent does four jobs that most teams already do manually: it turns messy inputs into structured facts, it retrieves relevant prior art and related filings for prior art search, it links every conclusion to evidence passages, and it produces drafts and checklists a professional can review quickly. It behaves like a patent drafting assistant that refuses to draft when the evidence is thin, and it shows its work when it does write.
In practice, that means the agent can produce artifacts like:
- An invention intake summary with the terms it plans to search and the terms it ignores (so a human can correct the scope).
- A prior art search shortlist with citations and a brief "why this matters" note per reference.
- Claim drafting notes that separate supported language from guesses and questions.
- A trademark screening pack that makes class and jurisdiction explicit before it talks about similarity.
Those artifacts matter because they change the workflow from "trust the answer" to "review the evidence", which is the only posture that survives deadlines and audits.
A generic chatbot fails in patent work for the same reason a generic search box fails: scope is ambiguous, the corpus is messy, and the cost of being confidently wrong is high. Patent and trademark decisions also sit on constraints the model cannot infer from a single prompt, such as jurisdiction, class of goods and services, publication lag, and the difference between what is registered and what exists only as practice.
We treated those constraints as product requirements. Instead of trying to produce a single "best answer", the agent is built to surface what it saw, what it did not see, and what it needs next to stay honest.
Search becomes reliable when the system remembers the right things in the right shape. We used Kernel Memory as the document and memory layer, then treated every ingest as a transformation into searchable pieces: text chunks with metadata, plus image-derived descriptions that can be reviewed and edited by a human.

Our ingestion pipeline is designed around a simple rule: if a professional cannot validate it quickly, it should not be fed into the model as a silent assumption. That rule changes how you handle images. A patent figure or a trademark logo is useful only after it becomes structured meaning, so we generate a plain-language description, attach it to the source image, and make it part of the review loop before it influences retrieval.
From there, retrieval is a multi-pass process that prioritizes "worth reading" over "looks similar".
- First pass: broad recall with metadata filters (jurisdiction, matter type, client, class).
- Second pass: reranking for the specific question and the specific claim language.
- Final pass: evidence packing, where the agent selects the passages it will cite and discards the rest.
The end product is deliberately smaller than a full corpus dump because the objective is to give a reviewer a short list they can trust enough to read.
You do not stop hallucinations by asking nicely, you stop them by making uncited output impossible to ship. We enforced a citation-first contract: the agent can draft, summarize, and flag risks only when it can attach each statement to a specific source passage, and it must switch to questions when the evidence is weak.
We used a few guardrails that stayed understandable for non-technical reviewers.
- Passage-level citations are mandatory for claim language and risk flags, not "nice to have".
- Abstain behavior is a feature, with an explicit "needs human review" output state.
- Retrieval scope is always shown (sources searched, filters applied, and what was excluded).
- Edits are first-class inputs, so reviewer corrections feed back into retrieval and drafts.
These guardrails matter because the failure mode in legal work is rarely a single wrong sentence. The failure mode is a plausible narrative that hides the uncertainty, then gets copied into an email, a filing, or a client update because it sounded clean.
The stack is intentionally simple and boring: C# and .NET for the service layer, Semantic Kernel for tool orchestration and agent flow, Kernel Memory for ingestion and retrieval, and Azure OpenAI for model reasoning and generation. The value is in how these pieces are wired into a review workflow, not in any single library choice.

Three external references define the technical baseline we worked from.
- Semantic Kernel (GitHub) (https://github.com/microsoft/semantic-kernel).
- Kernel Memory (GitHub) (https://github.com/microsoft/kernel-memory).
- Azure OpenAI data privacy (https://learn.microsoft.com/en-us/legal/cognitive-services/openai/data-privacy).
At runtime, Semantic Kernel acts as the dispatcher. It decides which tool to call next (retrieve, draft, ask clarifying questions, build a citation pack) and keeps the conversation state aligned with the workflow stage. Kernel Memory acts as the evidence store. It provides the chunks and citations, and it gives the agent a stable interface for "what we know" that is separate from the model.
We avoided impact claims that we could not verify from client data, so we wrote acceptance criteria instead. These are the measurements we recommend running before you let an agent touch production matters, along with the triggers that force a rollback.
- Citation coverage: 100% of drafted claim language and risk flags include at least one passage-level citation; sample 30 outputs per week; trigger a feature freeze if any uncited claim slips through.
- Abstain correctness: borderline cases produce questions or "needs review" outputs instead of guesses; review 20 borderline cases weekly; tighten prompts and retrieval when a guess appears more than once per week.
- Image traceability: every image-derived description is shown as an intermediate artifact and is editable; enforce on every run; rerun retrieval on edits and show the diff in the shortlist.
- Scope disclosure: every output states jurisdiction, class, and sources searched in plain language; enforce on every run; block export if scope is missing.
- Privacy boundary adherence: no raw client documents leave the Azure boundary; monitor continuously and spot-check monthly; trigger incident response on any detected leakage.
The key is that each metric has an observation window and an action trigger. Without those, teams end up arguing about "quality" in abstract terms while the tool quietly becomes a liability.
If we extend this system, the next work is not "more prompts". It is connectors, evaluation, and better interfaces for scope and review.
Three concrete next steps we typically prioritize:
- Add source connectors with explicit allowlists (patent corpora, internal DMS, and matter management systems).
- Build an eval harness that tests citation coverage and abstain behavior on real matter samples.
- Improve trademark screening UX so class and jurisdiction are forced inputs, not optional fields.
If you are planning a similar build and you want an agent that produces reviewable work product, the fastest path is to scope the retrieval boundary first, then design the outputs attorneys can review in minutes. If that is the conversation you want to have, reach us at contact (/contact).
It took the Managed Code team five months to build the application, as initially planned. The app that Managed Code developed runs smoothly, is highly rated by users, and helps the client generate a steady profit. The team was highly communicative, and internal stakeholders were particularly impressed with Managed Code's expertise.
Their professionalism and commitment to delivering high-quality solutions made the collaboration highly successful.
Thanks to Managed Code's efforts, the AI assistant significantly improved the client's ability to serve new and existing clients, resulting in increased customer satisfaction and higher sales. The team was responsive, adaptable, and committed to excellence, ensuring a successful collaboration
We're impressed by their expertise and their client-focused work.
With an excellent workflow and transparent communication on Google Meet, email, and WhatsApp, Managed Code delivered just what the client wanted. They effortlessly focused on the client's needs by being client focused, as well.