Konstantin Semenenko
June 23, 2026
5
minutes read
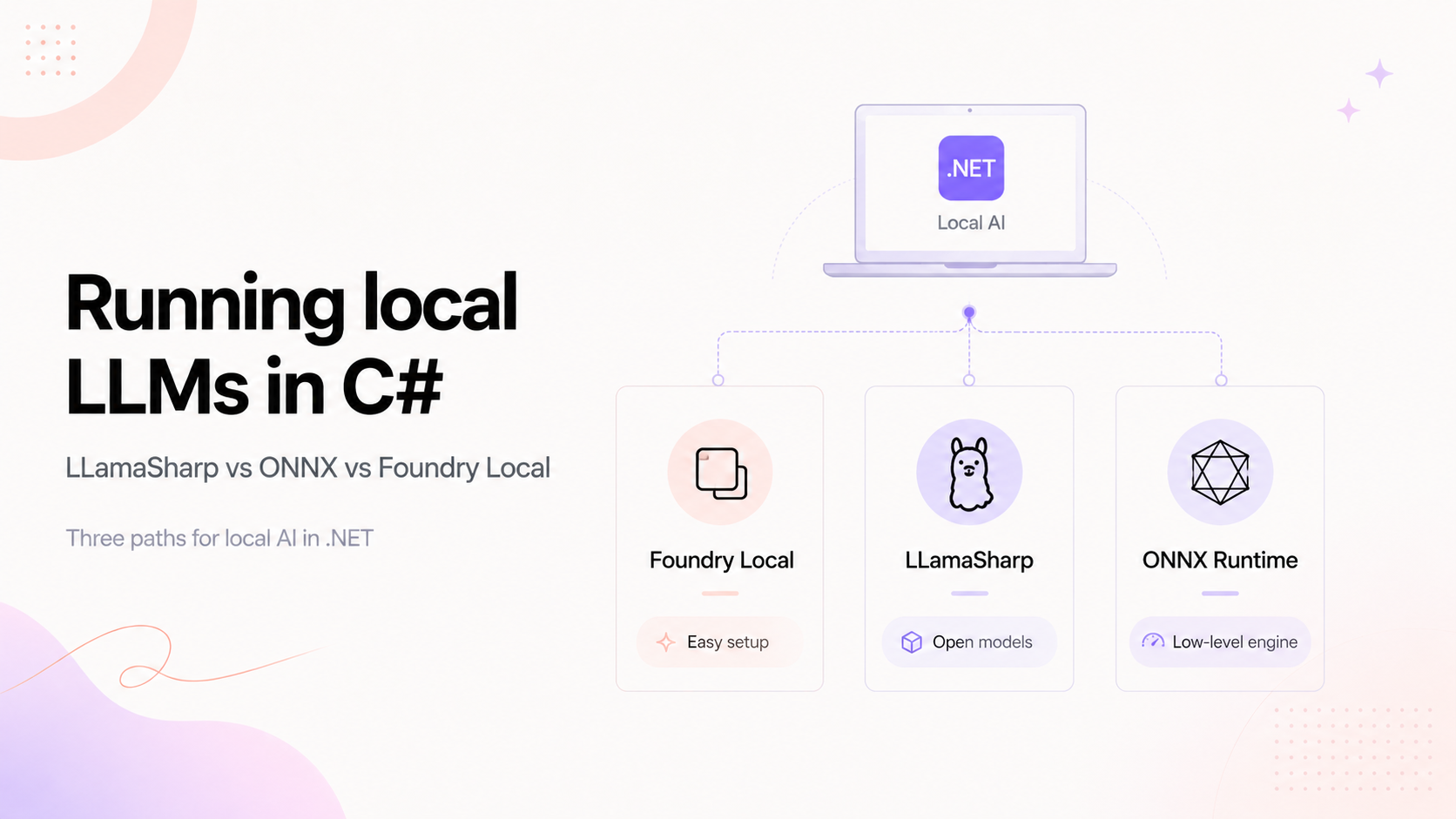
For local LLMs in C#, Foundry Local is the easiest managed path (a model catalog and automatic hardware optimization on top of ONNX Runtime), LLamaSharp is the most flexible for open GGUF models through llama.cpp, and ONNX Runtime is the engine underneath. All three plug in under Microsoft.Extensions.AI.




Running an LLM on your own hardware in .NET stopped being a research project. In 2026 there are three native ways to do it, and which you pick comes down to whether you want managed-and-easy or open-and-flexible. Here's how Foundry Local, LLamaSharp, and ONNX Runtime compare for local AI in C#.
For local LLMs in C#, Foundry Local is the easiest managed path (a model catalog and automatic hardware optimization on top of ONNX Runtime), LLamaSharp is the most flexible for open GGUF models through llama.cpp, and ONNX Runtime is the low-level engine the others build on. All three plug in under Microsoft.Extensions.AI, so your app code stays the same whichever you choose.
We ship private, on-device AI on .NET, so this is from running it, not reading about it.
Four reasons: privacy, cost, offline, and control. Privacy, because regulated or sensitive data can't go to a cloud API. Cost, because at high volume, local inference beats per-call pricing. Offline, because it runs with no network. Control, because you own the whole path. When any of those matters, local is the answer, and .NET does it natively now.
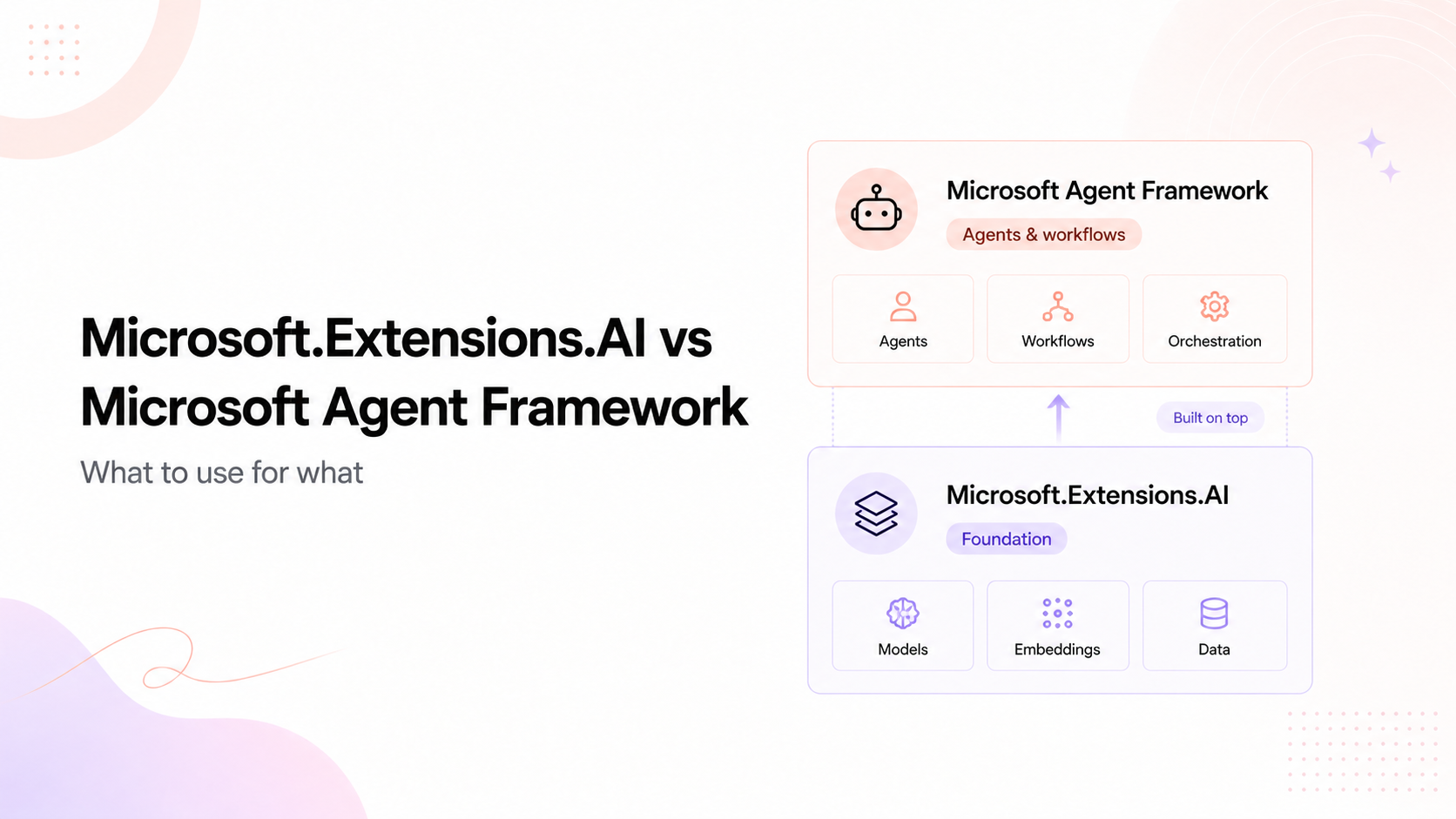
ONNX Runtime is the low-level inference engine that actually runs models, with hardware acceleration across CPU, GPU, and NPU through execution providers like CUDA, OpenVINO, QNN, and TensorRT. You can use it directly, with the ONNX Runtime generative AI extensions, when you want maximum control and performance and your model is in ONNX form. It's also what Foundry Local runs on underneath, so choosing Foundry Local means getting ONNX Runtime with the sharp edges handled for you.
Foundry Local is Microsoft's managed local runtime, built to make on-device inference simple. It detects your hardware and selects a hardware-optimized model automatically, pulls models from the Foundry model catalog, and on Windows wires up the right ONNX Runtime execution providers through Windows ML; on Apple Silicon it runs via Metal. It's self-contained: it adds only about 20 MB, needs no separate CLI on the user's machine, exposes an OpenAI-compatible API, can run as an optional local REST service, and even includes on-device Whisper audio transcription. In C# you add the Microsoft.AI. Foundry.Local package (or the WinML variant on Windows). It's the smoothest path when you want local AI to just work in the Microsoft stack.
LLamaSharp is the community C#/.NET binding over llama.cpp, and it runs the enormous ecosystem of open GGUF models, Llama, Qwen, Gemma, DeepSeek, Phi, and more, straight from Hugging Face. It's efficient on CPU and GPU through prebuilt backends (CPU, CUDA, Metal, Vulkan) with no C++ to compile, supports multimodal models like LLaVA, and has RAG support through its kernel-memory integration. You control models and parameters directly, including context size, GPU layers, and sampling. It's the most flexible option when you want open models and full control, with the trade that you manage more of it yourself.
Ollama is the easy external local runner: install it, pull a model, and .NET talks to it cleanly through Microsoft.Extensions.AI's OpenAI-compatible client. It's a great low-friction way to prototype local models, and many teams start there, then move to Foundry Local or LLamaSharp for a self-contained production build.
Match the tool to the priority. Easiest managed path in the Microsoft stack: Foundry Local. Maximum flexibility and open GGUF models: LLamaSharp. Lowest-level control and performance on ONNX models: ONNX Runtime directly. Fastest to prototype: Ollama. And because all of them sit behind Microsoft.Extensions.AI's IChatClient, you can start with one and switch without touching your app. That private, on-device approach is the same one in running AI agents privately. When you want a senior .NET team to build private, local AI, that's AI Dev Team.