Konstantin Semenenko
July 1, 2026
5
minutes read
$303K on AI in 29 days. The model wasn't the expensive part, the architecture around it was. Caching saved ~$169K; a cheaper API or our own GPUs would've cost the same or more. AI cost is architecture.




We spent $303,030.95 on AI in 29 days. And the model's price per token turned out to be almost the least interesting part of that number.
We were turning messy source data into clean, classified records at scale, the kind of job where you stop counting rows and start counting trillions of tokens. When the bill settled, more than 90% of it was language models. Functions, Postgres, storage, logs, all of it combined was the rounding error.
The model was the bill. So I want to walk through it honestly, because we came out with cost lessons I'd have paid a lot to know going in. Now you don't have to.
And the first lesson is the one nobody likes: the expensive part wasn't which model we chose. It was the shape of everything around it, what we sent, what we cached, what we filtered out, when we retried, and when we escalated. At real volume, that's where the money is.
The first decision was the one that mattered most: default everything to the cheapest model, reasoning off, and only escalate what actually fails.
So the workhorse was GPT-5 Nano: main summarization path, low verbosity, hard output cap, reasoning disabled. That last part was deliberate. Reasoning helps on hard edge cases, but at this volume it's a cost multiplier, hidden extra work, longer latency, pricier token behavior. It became an experiment setting, not a default. We turned it on when quality demanded it; the main lane stayed off.
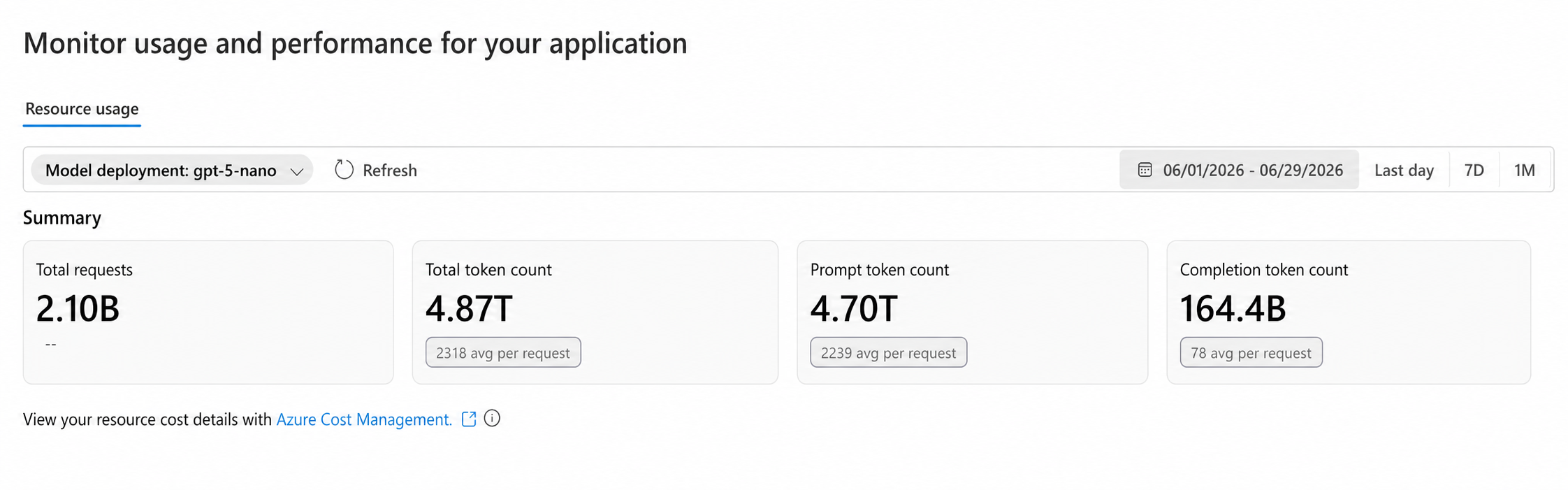
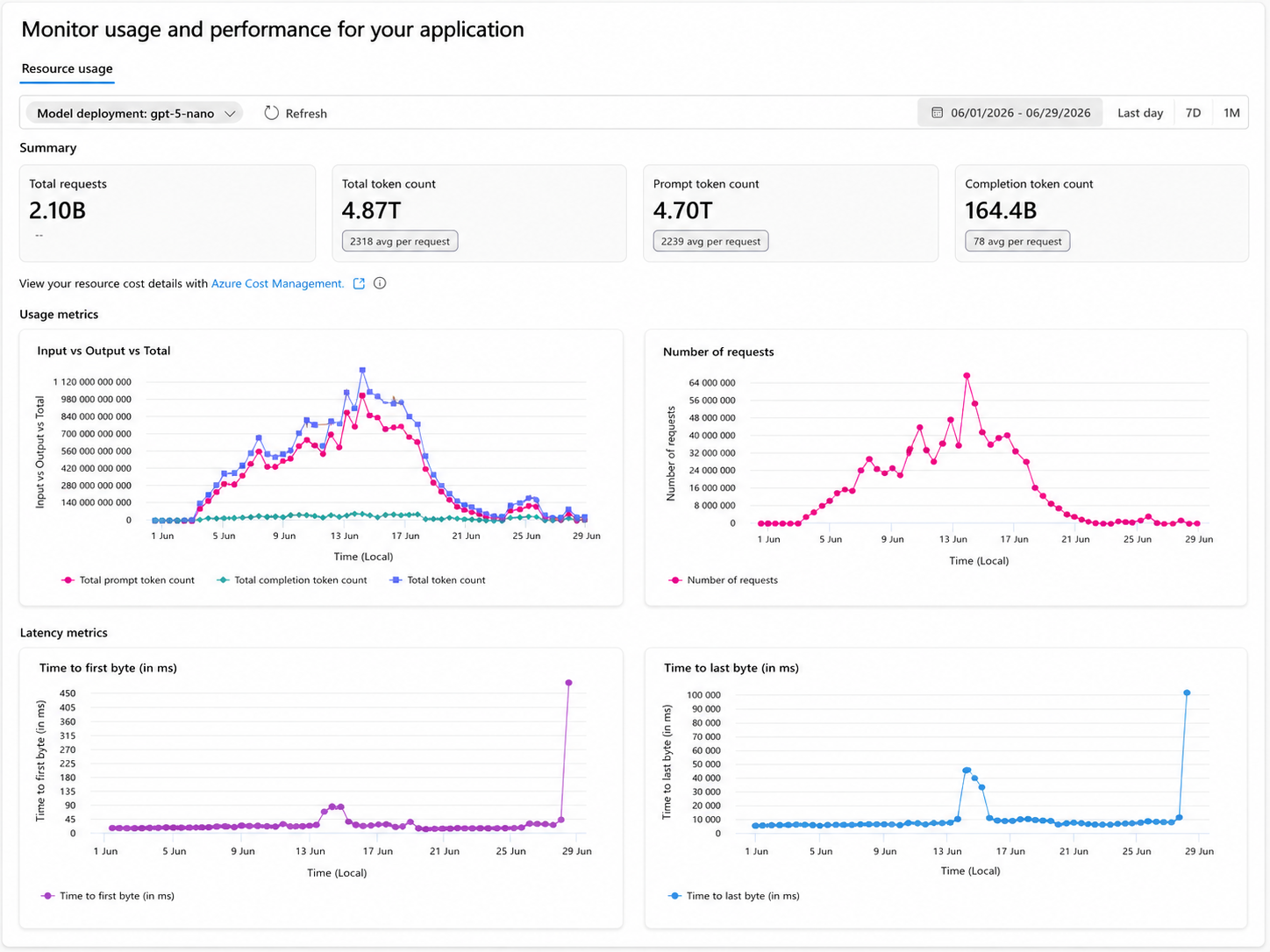
We also refused to fly blind. We logged every call: which model ran, input tokens, output tokens, and cost. Before each call we counted local tokens with a tokenizer; after, we stored the provider's reported usage, cached input included. Local counts tell you if a prompt is getting bigger; provider usage tells you what the bill will actually charge. You need both. And what that volume actually cost, broken down, is where it gets interesting.
Total token count is a comforting number and a useless one. Our run billed about 4.87 trillion model tokens, but that single figure hides where the money went. Split it the way the invoice does, into fresh input, cached input, and output, and the picture flips:
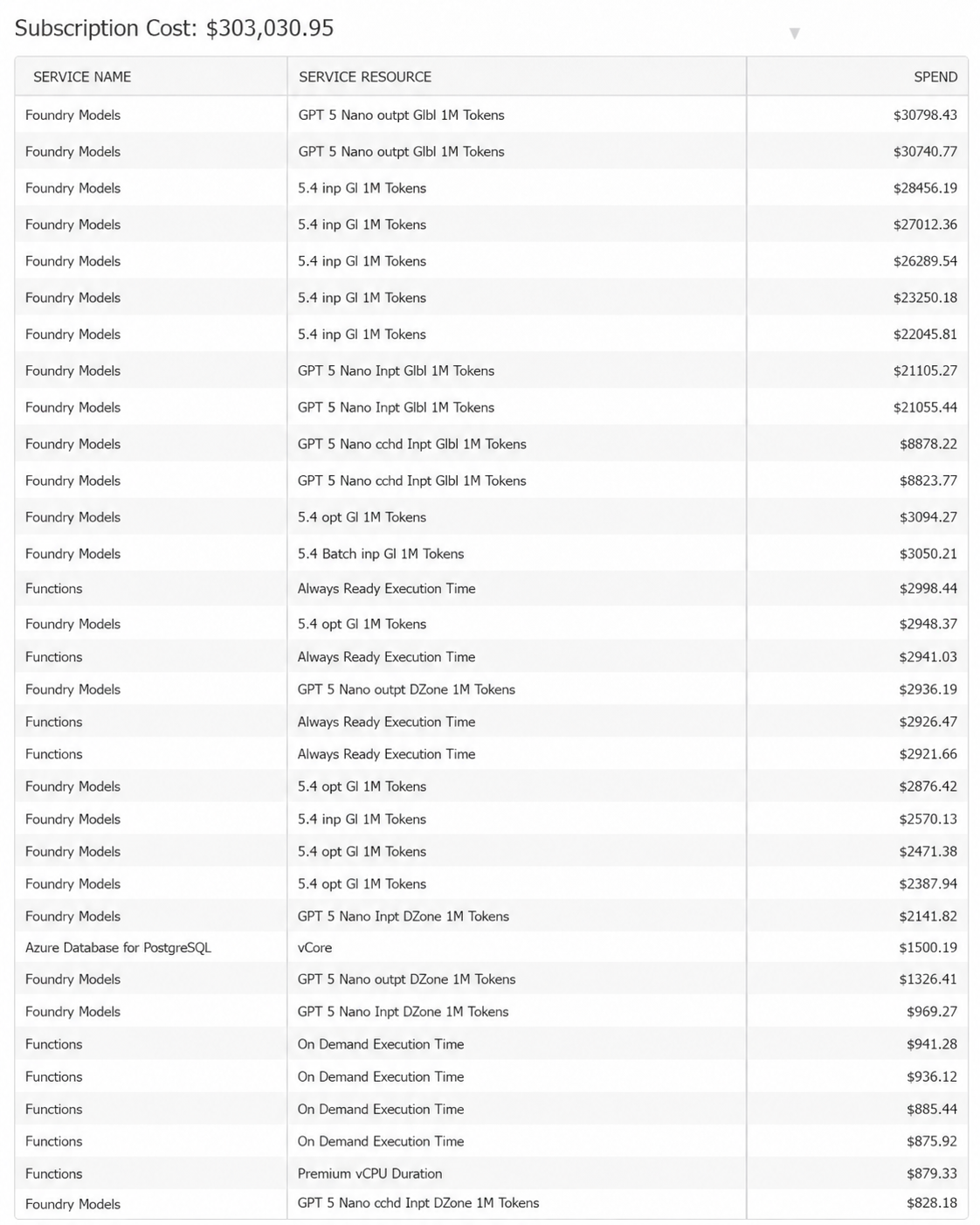
Fresh input: 953.6 billion tokens, $176,708. Cached input: 3.749 trillion tokens, $18,856. Output: 164.4 billion tokens, $80,044.
Now look at the mismatch. Cached input was 77% of all our tokens but under 7% of the cost. Output was 3.4% of the tokens and 29% of the cost. The cheap tokens dominate the volume; the expensive ones hide in a thin slice. If you track one blended token number, you are flying blind. You need at least these three buckets, because each has a different price and a different fix.
Then there's the split by model, and this is the one that stung. Nano handled almost the entire corpus: 4.81 trillion tokens for $129,880. The larger model (billed as GPT-5.4 in our Azure deployment) handled only the hard tail: 55 billion tokens, barely over 1% of the volume, for $145,724.
Read that again. One percent of the tokens. More than half of the model spend. Blended out, GPT-5.4 cost about 98x per token what Nano did, partly because Nano leaned so heavily on cheap cached input. A sliver of escalated traffic quietly owned the bill.
And the scale is its own lesson. 4.87 trillion tokens across two active weeks is about 348 billion tokens a day, or roughly 4 million tokens every second across the fleet. At that point you are not tuning a feature, you are running an industrial process, and a one-percent routing decision is a six-figure line item. At that point, 𝘈𝘐 𝘤𝘰𝘴𝘵 𝘪𝘴 𝘢𝘳𝘤𝘩𝘪𝘵𝘦𝘤𝘵𝘶𝘳𝘦.
The evaluation made the economics impossible to argue with. In one record-level eval, GPT-5 Nano scored 85.40 out of 100 at about $0.00006377 per record; the larger model scored 91.92 at about $0.00252326. A six-point quality gain, for roughly 40x the cost per record.
Six points is worth paying for on the hard tail. It's ruinous as a default. The big model was never expensive because it existed; it was expensive when too much traffic reached it.
A raw record is rarely one clean task. A single file, batch, or payload often bundles several unrelated pieces, plus junk: empty fields, duplicates, malformed rows, unsupported languages, content too short to matter. Send the whole thing and you pay more for a worse result.
So the pipeline splits inputs into coherent units and drops the obvious junk in plain code before the model is ever called. That's the cheapest optimization there is. Rows filtered before the LLM cost zero tokens.
This one surprised the team most, and it sounds too small to matter until you multiply it by a few billion.
You pay per token, and a token is only a few characters. So nearly every character you add turns into tokens you pay for, on every row, on every pass. Punctuation, pretty-printing, verbose field names, all tokens.
The worst offender in our data was identifiers. The records were keyed by GUIDs, things like b1386248-975a-464c-91e5-06f1f6415cd4. A GUID like that tokenizes to around 20 tokens, so a list of a thousand rows spends ~20,000 tokens on identifiers alone, before a single useful word. The fix is dumb and effective: stop sending them. We leaned on source order instead of internal IDs, and for the taxonomy we let the model return compact codes like 'f:.91' or '3v:.88' that the app mapped back to full slugs like 'sport' or 'track_and_field'. That cut both input and output, and it reduced format drift, because the model had fewer long labels to mistype.
If one mechanism saved this project, it's prompt caching. And it inverted an instinct.
Normally you keep the system prompt short. But if the same prefix repeats byte-for-byte across billions of requests, a bigger system prompt becomes fine, because it's cacheable. So we did the opposite of the usual advice: everything stable went into the system prompt, output format, field rules, taxonomy, limits, examples, safety, and only the changing part, the record itself, stayed in the user message.
That gave us a big repeated prefix Azure could cache. It wasn't theoretical. In production-shaped tests, one request cached 213,504 of 335,164 input tokens; another cached 324,864 of 381,742. In the pricing tier we were on, fresh input ran $0.05 per million tokens and cached input $0.005, a tenth of the price. (Azure rates vary by model, region, and data zone, so treat these as our numbers, not a universal table.)
Across the run, 3.749 trillion of our input tokens were billed as cached. We paid $18,856 for them. At fresh-input rates for the same model and zone mix, those tokens would have cost about $188,556. Caching avoided roughly $169,700 of model spend. One mechanism.
The discipline that makes it work: every request has to look alike. One system prompt, one format, one allow-list, so the cache actually hits and the bill stays predictable instead of approximate.
Caching rescued the input side. Output gets no such discount: every output token is billed in full, every time. Remember, output was just 3% of our tokens but 29% of the model cost, so it's the last place you want waste.
The model should emit a protocol, not a pretty schema. The instinct is clean JSON, because it's nice for the app: { "topic": "sport", "subtopic": "track_and_field" }. But the quotes, braces, and long field names are output tokens you pay for on every row. Let the model emit two short lines instead, T=f and S=track, with the legend ('T' is topic, 'f' is the code for sport) living once in the cached system prompt. Cheaper, and fewer long labels for the model to mistype.
One caution we learned the hard way: shortest is not the goal, smallest reliable is. A too-clever format that breaks on an edge case (CSV is cheap until a stray comma shifts every column) triggers a parse failure, and a parse failure is just another paid call to repair it. 𝘍𝘰𝘳𝘮𝘢𝘵 𝘥𝘦𝘴𝘪𝘨𝘯 𝘪𝘴 𝘍𝘪𝘯𝘖𝘱𝘴.
At this scale, retry policy is cost policy. The pipeline retries rate limits carefully, respects retry timing, and fails over between Azure Foundry resources instead of sitting and waiting. But it does not blindly retry everything. Bad formatting, empty responses, model-side rejections, and non-rate-limit failures get recorded, not repaired with another paid call. For content-filter failures it tries exactly one conservative rewrite, then stops. That's what keeps a single hard record from turning into an unbounded series of paid requests.
The obvious reaction to a bill like this is "we're on the wrong platform." So we ran the actual math on our actual volumes: 4.7 trillion input tokens, 164 billion output tokens, 4.87 trillion in total, over about two active weeks. Three real options, with real numbers from Together's published pricing.
𝗢𝗽𝘁𝗶𝗼𝗻 𝟭: 𝗮 𝗰𝗵𝗲𝗮𝗽𝗲𝗿 𝗔𝗣𝗜. Together's cheapest capable small model, gpt-oss-20B, lists at $0.05 per million input and $0.20 output. Input: 4.7T x $0.05 = $235,131. Output: 164B x $0.20 = $32,888. Total: about $268,000. Through Together's batch lane, roughly half: about $134,000. That's the same neighborhood as our Azure bill, and the reason stings: Together's small models have no caching discount, so we'd pay full price on all 4.7 trillion input tokens, the exact ones Azure billed at a tenth. Time isn't the problem here: the provider runs the fleet, so wall-clock stays in days, the same order as our run, with nothing to manage.
𝗢𝗽𝘁𝗶𝗼𝗻 𝟮: 𝗿𝗲𝗻𝘁 𝗛𝟭𝟬𝟬𝘀 𝗮𝗻𝗱 𝗿𝘂𝗻 𝗮𝗻 𝟴𝗕 𝗺𝗼𝗱𝗲𝗹 𝘆𝗼𝘂𝗿𝘀𝗲𝗹𝗳. Together's H100 cluster lists at $3.09 reserved to $3.99 on-demand per GPU-hour. Assume a batched 8B sustains about 15,000 tokens per second on one H100. Then 4.87 trillion tokens is about 90,000 GPU-hours. Compute: $278,000 to $360,000. Time on a single H100: about 90,000 hours, or 10 years. To match our two-week window: about 270 H100s in parallel, non-stop. To do it in one week: about 540. The dollar figure barely moves with the GPU count, it's the same 90,000 GPU-hours; what you're really buying is the ability to stand up and saturate a few hundred H100s without a gap.
𝗢𝗽𝘁𝗶𝗼𝗻 𝟯: 𝗰𝗵𝗲𝗮𝗽𝗲𝗿 𝗰𝗼𝗻𝘀𝘂𝗺𝗲𝗿 𝗰𝗮𝗿𝗱𝘀. RunPod lists RTX 4090s near $0.69 an hour, a fraction of an H100. But a 4090 pushes far fewer tokens per second; at roughly 5,000 it needs about 270,000 GPU-hours for the same work. Compute: about $187,000. Time on a single card: about 31 years. To finish in two weeks: about 800 cards. The cheap hourly rate gets eaten by needing five times the hours and eight hundred cards to schedule.
Put it side by side. The API lands around $134K to $268K. Your own H100s land around $280K to $360K, plus a 270-GPU cluster to babysit. Cheap cards land around $187K, plus 800 of them. Every escape route ends up in the same neighborhood as the bill we already paid, and adds the reliability, monitoring, and eval work the managed API was doing for free. The platform is not the lever. Caching alone, one architecture decision, kept about $169,700 off this bill, more than any provider switch on the menu would have saved.
• Default to the smallest model, reasoning off.
• Escalate only the failures, and watch the escalation rate. It's your biggest lever.
• Filter junk rows in code before the model. The cheapest token is the one you never send.
• Cache the repeated prefix. Push stable rules into the system prompt so cached reads bill at a tenth of the price.
• Shrink the payload. Source order or short codes instead of GUIDs, no pretty-printing, short field names.
• Cap and shape the output. It costs far more than input, about 8x on Nano, and it never caches.
• Batch what isn't real-time, at roughly half price. We've started moving the heavy model onto this lane.
• Price a cheaper provider or your own GPUs before you migrate. On our volumes both landed in the same range as the bill. Architecture moves the number far more than the platform.
• Make retries deliberate. Retry rate limits, not failures you'll just pay to repeat.
• Measure cost per accepted result, not cost per token. It absorbs the retries, repair calls, and escalations that per-token hides.
At this volume, 𝘈𝘐 𝘤𝘰𝘴𝘵 𝘪𝘴 𝘢𝘳𝘤𝘩𝘪𝘵𝘦𝘤𝘵𝘶𝘳𝘦. Not a slogan. A budget line.
Here's the trap the pricing page sets. It shows you one thing: the price per token. But that number barely moved our bill. What moved it was everything the price page never mentions: how much traffic escalated, whether the prefix was stable enough to cache, how long the output ran, how many tokens went to identifiers, how often a broken format paid for a retry. 𝘛𝘩𝘦 𝘱𝘳𝘪𝘤𝘦 𝘭𝘪𝘴𝘵 𝘴𝘩𝘰𝘸𝘴 𝘺𝘰𝘶 𝘵𝘩𝘦 𝘮𝘰𝘥𝘦𝘭. 𝘛𝘩𝘦 𝘪𝘯𝘷𝘰𝘪𝘤𝘦 𝘴𝘩𝘰𝘸𝘴 𝘺𝘰𝘶 𝘺𝘰𝘶𝘳 𝘴𝘺𝘴𝘵𝘦𝘮.
So we ran the obvious gut-check: were we even on the right platform? We priced every escape route on the exact same 4.87 trillion tokens, over the same two weeks. The scoreboard:
→ Azure, with caching (what we actually paid): $275,608 · 91% of the bill → Cheapest API swap (Together gpt-oss-20B): $268,000 ($134,000 batched) · no caching, so full price on all 4.7T input → Rent our own H100s: ~$280,000–360,000 of compute · plus 270 GPUs in parallel for two weeks (one card: 10+ years) → Cheap consumer cards: ~$187,000 · only if you can find and babysit 800 of them
Read that twice, because it's the whole point. Every alternative lands in the same neighborhood as what we already paid, and every one of them hands you a second job: reliability, monitoring, failover, evals, a cluster to keep alive at 4 million tokens a second. Azure came with all of that built in, plus the one lever that actually bent the number: caching, which quietly saved about $169,700. No provider switch on that list saves you that.
So no, we weren't on the wrong platform. We ran it on Azure because, once the architecture was right, Azure was simply the cheapest place to put it. The platform didn't save us. The architecture did, and Azure was the platform that rewarded it.
And that's the part to take with you: a bill like this doesn't happen to you, you design it. Caching alone was the difference between $276K and $445K. Routing kept the expensive model on 1% of the traffic instead of all of it. Same models, same prices, same tokens. 𝘛𝘩𝘦 𝘴𝘺𝘴𝘵𝘦𝘮 𝘺𝘰𝘶 𝘸𝘳𝘢𝘱 𝘢𝘳𝘰𝘶𝘯𝘥 𝘵𝘩𝘦 𝘮𝘰𝘥𝘦𝘭 𝘪𝘴 𝘵𝘩𝘦 𝘣𝘪𝘭𝘭.
We do this for clients now: designing that cost structure before a feature ships, so the first big invoice isn't the moment you find out how it behaves at scale. If you're about to put serious volume through a model, do the math before the invoice does it for you. Happy to compare notes.